
Předevčírem jsme se vrátili z Datafesťáku, akce pořádané Keboolou, Českou spořitelnou a Univerzitou HK. Jsme trochu unavení, ale rozhodně plní dojmů 🙂
Asi před měsícem nám napsal Pavel Doležal z Kebooly, jestli bychom nemohli přijet koncem listopadu do Hradce Králové a nepomohli na Hackatonu Datafesťáku. Souhlasili jsme, i když jsme neměli moc velkou představu, co nás čeká. Měli jsme dát k dispozici Interpretora, což je naše cloudová služba analyzující text. No a samozřejmě bysme pomáhali těm, kdo jí budou chtít vyzkoušet.
Fesťák začal minulý pátek ráno a my na něj dorazili těsně před začátkem Keynote Petra Šimečka alias Padáka z Kebooly. To znamená právě včas, abychom si užili, jak Padák mluví o Geneee mezi spoustou velkých a známých firem.

Data
Krátce před akcí jsme zjistili, že žádný z poskytnutých datasetů neobsahuje textová data. Což byl samozřejmě problém, protože technologie na zpracování textů se bez textů docela težko používá. Po rychlé středeční poradě jsme se rozhodli, že přineseme nějaká data sami a nakonec padla volba na stenozáznamy z jednání Poslanecké sněmovny Parlamentu ČR. Bylo to trochu kontroverzní – přece jen většina lidí nemá o naší politické scéně valné mínění, ale dopadlo to skvěle. Navíc web psp.cz poskytuje kromě stenozáznamů také některé strukturované informace jako kdo kdy byl přítomný ve sněmovně, kdo jak hlasoval a další.
Datový hackathon měl začít až v pátek večer, takže jsme měli během přestávek mezi výbornými přednáškami ještě trochu času data ze Sněmovny vyladit. O tom, že jsme kromě Interpretora přivezli i data, nikdo včetně organizátorů nevěděl. Bylo přijemné slyšet rozruch, který představování v sále způsobilo.
Hackathon
Interpretora nakonec použili tři týmy: dva na analýzu dat ze Sněmovny a jeden na analýzu konverzací účastníků hackathlonu ve Slacku.
Snažili jsme se všem vysvětlit možnosti i limitace naší platformy a vůbec jim být po ruce. Do spacáků mezi lavicemi v jakési učebně jsme zalehli až dlouho po půlnoci. Ráno nás vzbudili studenti univerzity třetího věku, kteří nad námi seděli a připravovali se na test z účetnictví 🙂

Sobotní seminář Jirka pojal jako úvod do NLP obecně. Ačkoliv spoustu věcí ve zpracování přirozeného jazyka vypadá jako snadná záležitost, téměř pro všechno existují výjimky z pravidel a může se z toho stát pěkné peklo. Přestože tohle povídání kolidovalo s časem večeře, všichni vypadali, že je to baví a málem na nás nic nezbylo 🙂
Jak to dopadlo
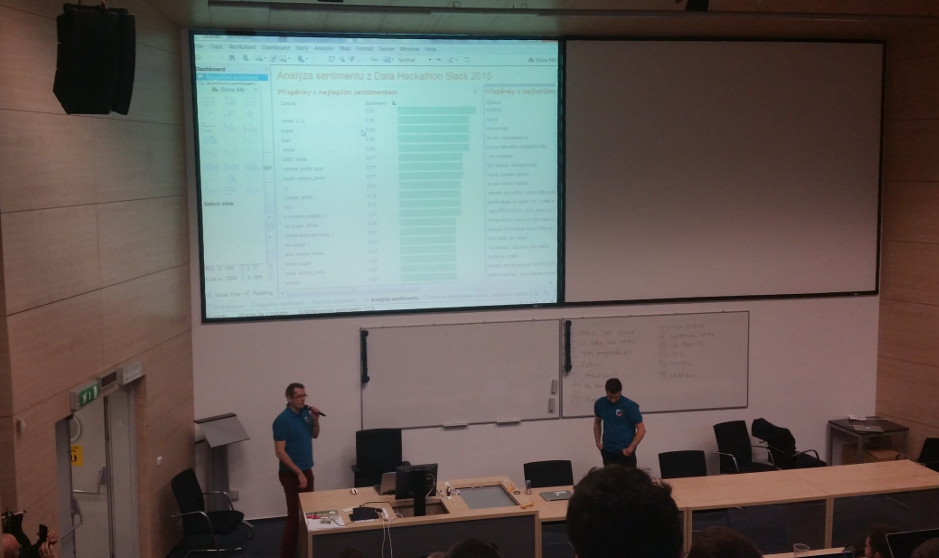
První tým (Dolphin consulting) analyzoval všechny příspěvky ve Slacku. Hledal ty nejvíce pozitivní a nejvíce negativní, hledal kdo z účastníků je celkově pozitivní a kdo spíše negativní.

Druhý tým (nomorecoolnames) zjišťoval z proslovů ve Sněmovně různé pohledy – účast na jednáních, hlasování, kdo o kom mluví, kdo je pozitivní a kdo negativní.

Třetí tým zanalyzoval vulgárností ve sněmovně. Závěrem bylo, že poslanci jsou na půdě sněmovny víceméně slušní. 🙂
Shrnutí
Jsme rádi, že jsme mohli ukázat možnosti NLP, Geneea i Interpretora, a že mnoho přítomných, se kterými jsme mluvili, mělo spoustu nápadů, jak to využít. Dívat se na data bylo pro všechny naprosto přirozené, ale přihodit k tomu nestrukturovaná data přidalo spoustu zábavy 🙂
No a samozřejmě musíme poděkovat organizátorům, kteří akci perfektně zvládli. Jsme moc rádi, že Pavel Doležal, Vojta Roček, Petr Padák Šimeček, Jirka Tobolka a další si našli čas a měli nervy a odvahu fesťák uspořádat.