Customizable
Use your own dictionaries, labels, and categories. Have your own private analyzer tuned to your data and your needs.

Use the artificial intelligence of the Interpretor, our NLP engine, to find out what's in customer feedback, news articles, social media posts, blogs, emails, or legal documents in your archives. Discover how powerful, customizable, and scalable it is.
See our demo now!
Trusted by
Use your own dictionaries, labels, and categories. Have your own private analyzer tuned to your data and your needs.
Use our REST API to integrate the Interpretor capabilities into your workflow, or use an SDK.
Preconfigured for news, hospitality, banking and more.
Calling the Interpretor from Keboola Connection is a matter of a few clicks.
Find the appropriate dictionary form and part of speech for each word.
Identify a customer’s expected problem or desired action and connect your chatbot.
Sort texts into predefined categories. Use industry-standard categories such as IAB, IPTC, our out-of-the-box categories for restaurant VoC, or your own custom labels.
The public API supports English, Czech, Dutch, French, German, Polish, Portuguese, and Slovak.
Support for Spanish is in beta.
We are able to add support for a new language in two weeks if required.
The Interpretor uses a pipeline of modules to analyze each document. We use a combination of machine learning modules (neural networks, support vector machines, conditional random fields, maximum entropy, etc.), rule-based models, and large knowledge bases to obtain the best possible results. Both the pipeline and the individual modules can be customized for a particular use-case.
Step 1
Step 2
Step 3
Step 4
Everything you need to integrate Geneea’s Interpretor into your solution
GET FREE API TRIAL
On October 28–29, the Paris AI Forum 2025, organized by WAN-IFRA (the World Association of News Publishers), took place and Jirka Hana was there. In addition to enjoying great talks, French cuisine, and views of the Eiffel Tower, he met with Geneea’s partners and discussed the future of AI in news media with other participants....

Parliamentary elections took place in the Czech Republic last Friday and Saturday. For Geneea, this was an important period — since 2020, we’ve been actively involved in reporting election results. For the Czech News Agency (ČTK), we automatically and in real time generate articles with both interim and final results, allowing journalists to devote more...
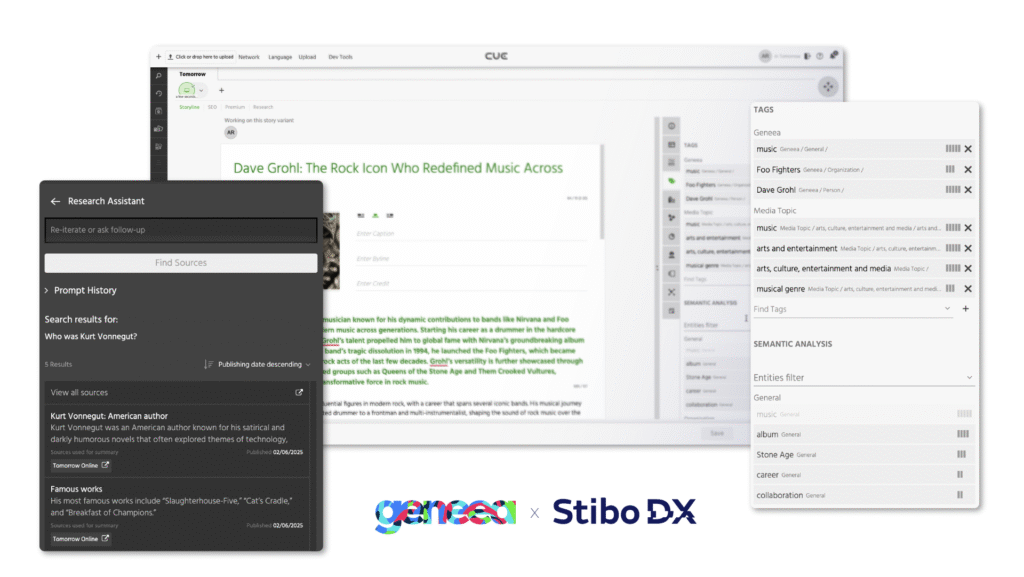
Geneea and Stibo DX are proud to announce a major milestone in their collaboration: Geneea has become an official technology partner of Stibo DX, marking the beginning of a closer product and business relationship. This partnership formalizes years of successful cooperation and shared innovation between the two companies. By combining Stibo DX’s industry-leading content management...
